
// עומר קורן, מנכ"ל ווביקס, צוות AI מפא"ת //
תקציר מנהלים
בפוסט זה נסקור מודל חישובי שאימנו, מבוסס למידת מכונה, לחיזוי התוצאות של בדיקות PCR לקורונה על סמך תסמינים, מדדים ונתוני רקע בלבד. המודל אומן על דאטה-סט פתוח שנאסף בארה"ב – דאטה-סט מפורט ואיכותי, אך קטן יחסית ומונה כ- 1,600 בדיקות PCR בלבד. התוצאות מראות פרדקטביליות גבוהה. למרות מיעוט הנתונים, המודל שאימנו חוזה את תוצאת הבדיקה בהסתברות של כ- 70%. אימון המודל על דאטה-סט גדול בשני סדרי גודל ומעלה עשוי, להערכתנו, להביא לביצועים טובים מאוד ולאפשר ביצוע "בדיקות וירטואליות" לקורונה. בדיקות וירטואליות כאלו יסייעו בתעדוף חכם של הבדיקות ובסגירת מעגלי החלטה ובידוד של נבדקים מובהקים – ובכך יאיצו את תהליכי היציאה מההסגר וישפרו את יכולת ניטור מצב התחלואה בשגרת הקורונה החדשה ובמקרים של התפרצויות נוספות של הנגיף.
מדינת ישראל יכולה להוביל בעולם בתחום זה – והחסם היחיד הינו חסם של נתונים ולא של טכנולוגיה. מומלץ להשקיע בהקדם משאבים משמעותיים בתיעוד מפורט ומדויק של נתוני הבדיקות והנבדקים ולפרסם את הנתונים לציבור הרחב תוך שמירה על פרטיות הנבדקים. נתונים כאלו, אם יאספו, יטוייבו ויפורסמו, יאפשרו לרתום את כוחה האדיר של קהילת הדאטה-סיינס בארץ ובעולם לטובת ייעול מהלכי היציאה וניטור התחלואה – בקלות ובמהירות.
תזכורת
בפוסט הקודם, הוצע לבחון שימוש בשיטות למידת מכונה על מנת לתעדף בצורה חכמה יותר את תור בדיקות ה- PCR לקורונה ועל מנת להחליף חלק מן הבדיקות בבדיקות וירטואליות. עשינו שימוש בנתונים שפורסמו על ידי צוות תמנ"ע במשרד הבריאות וכללו מעל 100 אלף בדיקות, ואימנו מודל חישובי לסיווג התוצאות לתוצאות חיוביות או שליליות לקורונה. המודל קיבל כקלט נתונים על הנבדק, התסמינים והאינדיקציה שהובילה לביצוע הבדיקה, וחזה כפלט את ההסתברות לתוצאה חיובית ושלילית.
מצד אחד, המודל שאימנו הגיע לרמות דיוק טובות מאוד ביחס לנתונים שפורסמו (AUC=0.91). מצד שני, התוצאות שהראינו אינן ניתנות להכללה "לעולם האמיתי" בצורה ישירה, בעיקר בשל שני עיוותים:
- הדאטה שפורסם על ידי משרד הבריאות סובל מהטיית דיווח משמעותית. בשל מכניזם איסוף הנתונים – נבדקים שתוצאתם חיובית סובלים מדיווח יתר של תסמינים מחד, ונבדקים שתוצאתם שלילית סובלים מדיווח חסר של תסמינים מאידך. ההטיה הזו גורמת לכך שהמודל שלנו עשה שימוש בתסמינים כמנבא מובהק לתוצאת הבדיקה – בעוד שבעולם האמיתי, ככל הנראה, הערך הניבויי של תסמינים, גם אם קיים, הינו פחות.
- הדאטה שפורסם על ידי משרד הבריאות הוא רזה במיוחד. כל בדיקה כוללת רק מעט מאפיינים על הנבדק, התסמינים והסיבה לביצוע הבדיקה. סביר להניח שנתונים נוספים וברמת פירוט גבוהה יותר – יכולים לאפשר אימון מודל חזק יותר ובעל כושר ניבוי רב יותר.
הפוסט הקודם הדגים את הפוטנציאל הרב הטמון בחיזוי תוצאות הבדיקה. הפרסומים האחרונים על שגיאות בחלק מהבדיקות, לצד דיווחים על חסמים בהגדלת כמות הבדיקות וקצב הפענוח שלהן – רק ממחישים את הפוטנציאל והצורך במנגנון של בדיקות וירטואליות. עם זאת – מכיוון שהתוצאות שהראינו מתבססות על דאטה מוטה וחלקי ברור כי לא ניתן להכליל ישירות מהעבודה שלנו אל העולם האמיתי.
בדיקות PCR, על כל השרשרת שלהן, הינן משאב יקר ובמחסור. ציוד הבדיקה (מטושים, ריאגנטים), צוותי הדגימה, מעבדות הפענוח, מערך התיעוד והדיווח – כל אלו הינם משאב במחסור. מימוש של תוכניות ואסטרטגיות היציאה מותנה ביעילות של מערך הבדיקות. היכולת לבצע כמות מספקת של בדיקות ולפענח אותן מהר מספיק – תגדיר במידה רבה את קצב החזרה של המשק לפעילות מלאה ואת יכולת הניטור והשליטה בהתפרצויות נוספות של הנגיף, אם וכאשר יתרחשו. אם אכן ניתן להגדיל אפקטיבית את כמות הנבדקים באמצעות בדיקות וירטואליות מבוססות למידת מכונה – לדעתנו זו תהיה טעות גדולה לא להבין את זה, רק בגלל שהדאטה שפורסם הוא מוטה וחלקי.
על רקע המוטיבציה שתוארה לעיל, איתרנו דאטה-סט אחר, מתאים להמשך בחינת הרעיון – והתוצאות המוצגות כאן מתבססות עליו.
הדאטה-סט
כמה עובדות חשובות על הדאטה-סט שבו עשינו שימוש בפוסט הנוכחי:
- הוא מתוחזק על ידי Braid Health ו- Carbon Health, שתי חברות אמריקאיות מאיזור סן-פרנסיסקו שמספקות שירותי בריאות ובכללן איבחון, בדיקות, דימות וטיפול רפואי.
- הוא קטן יחסית וכולל, נכון לרגע זה, 1,610 רשומות – 1,610 בדיקות PCR שבוצעו לקורונה. מתוכן 1,509 בדיקות שתוצאתן שלילית ו- 101 בדיקות שתוצאתן חיובית לקורונה.
- הוא עשיר מאוד. כל רשומה כוללת מגוון נתונים, ובכלל זאת נתוני רקע על הנבדק, נתונים על האינדיקציה האפידמיולוגית שהובילה לבדיקה, מדדים גופניים, תסמינים קליניים ונתונים על קומורבידיות (או בשמן הישראלי המוצלח אף פחות "מחלות רקע").
- חלק מהרשומות כוללות גם קישורים לצילומי דימות רנטגן חזה ולפענוח שלהם – נתונים בהם לא ביצענו שימוש בניתוח הנוכחי.
- עושה רושם שהגופים שמתחזקים אותו הינם בעלי תודעה טכנולוגית גבוהה ותודעת דאטה גבוהה. מהניתוחים שלנו לא איתרנו חוסרים או הטיות מובהקים.
- הוא שומר על פרטיות הנבדקים ועומד, לפי המפרסמים, בתקן HIPAA לאנונימיות של מידע רפואי דיגיטלי.
- הוא מפורסם בקוד פתוח תחת רישיון Creative Commons.
- בכוונת Braid Health ו- Carbon Health להמשיך ולפרסם עדכונים לדאטה-סט, בתדירות של כאחת לשבוע.
מה אנחנו רוצים להשיג? גישה ומטרה
מטרת הניתוח המובא בפוסט הנוכחי היא להמשיך ולבחון את הישימות של הרעיון שלנו – האם ניתן לאמן מודל למידת מכונה לביצוע בדיקות וירטואליות שיחזה חלק מהתוצאות של בדיקות ה- PCR לקורונה ברמות גבוהות של דיוק, רגישות וספציפיות, יאפשר תעדוף חכם של תור הבדיקות ויאפשר החלפה (זמנית או קבועה) של חלק מהבדיקות, אלו שתוצאתן מובהקת, בבדיקות וירטואליות?
חשוב כבר עכשיו, כנגזרת מהמטרה הזו, להבין מה אנחנו לא עושים:
- זו לא תחרות קאגל. אין לנו סט מבחן פרטי או פומבי (Public / Private Test Set) שעליו נבדוק את התוצאות. המטרה שלנו היא לא "לסחוט" כל פרומיל אפשרי של מדד דיוק כזה או אחר ואין כאן Leaderboard שידרג את התוצאות שלנו ביחס לתוצאות אחרת. המטרה שלנו היא בעיקרה תיאורית ומחקרית, הדאטה-סט שלנו קטן יחסית, ולכן נרשה לעצמנו להשתמש בנתונים כולם כדי לבחון מספר מדדים והיפותזות. ברור לגמרי שלא נצא מכאן, אחרי שאימנו מודל על 1,610 רשומות, עם מודל שיכליל בצורה מלאה וישירה לעולם האמיתי. אם נצליח לאמן מודל שיראה כושר ניבוי סביר, על הדאטה הקטן הזה, זה יהיה כיוון טוב מאוד. מה זה "מודל שיראה כושר ניבוי סביר"? לפי המאמר הזה, מודל סיווג בינארי עם AUC גבוה מ- 0.7 נחשב ל"קביל" (0.7 – 0.8: קביל, 0.8 – 0.9: מצויין, מעל 0.9: 'אאוטסטנדינג').
- זה לא פוסט שיווקי. "If you torture the data long enough, it will confess to anything", לימד אותנו הנובליסט רונלד קוז. "You juke the stats, and majors become colonels", היגג הבלש רונלד 'פרז' פריזבילסקי מהסמויה. ואכן, קל מאוד להריץ מודל חזק מדי, לעשות Overfit לדאטה ולהראות תוצאות מרשימות מאוד מבחינה שיווקית (וחסרות ערך מבחינה מהותית). אנחנו לא שם.
אז מה כן? יש לנו מעט דאטה, טוב יחסית. ננסה לאמן מודל חיזוי, או ליתר דיוק אנסמבל של מודלים, פשוטים יחסית. ננסה "להחזיק" את המודלים פשוטים מספיק על מנת למנוע Overfitting קיצוני מדי. ננסה לראות אם המודל מראה קשר ניבוי מעניין בין מאפייני הקלט לבין משתנה המטרה. ננסה להבין האם על סמך מאפייני הנבדק, מאפייני הרקע האפידמיולוגי שהובילו לביצוע הבדיקה, מחלות הרקע, המדדים והתסמינים – ניתן לחזות ברמת וודאות טובה אם הנבדק יהיה חיובי או שלילי לקורונה.
אקספלורציה ותיאור של הדאטה-סט
הדאטה-סט כולל, כאמור, 1,610 רשומות, מתוכן 1,509 רשומות של בדיקות שליליות ו- 101 רשומות של בדיקות חיוביות לקורונה. תמרור אזהרה ראשון – מדובר בדאטה לא מאוזן (Imbalanced), נצטרך לתת על כך את הדעת.
המאפיינים של כל בדיקה מחולקים לשש קטגוריות של מאפיינים: נתוני רקע, מדדים גופניים, תסמינים קליניים, נתוני קומורבידיות, נתונים על הבדיקה עצמה ותוצאות הבדיקה. בטבלה שלהלן סיכמנו את המאפיינים בהם ביצענו שימוש (פרטים מלאים על המאפיינים מופיעים במילון שצורף לדאטה-סט).
| קטגוריה | מאפיינים |
| נתוני רקע על הנבדק ועל האינדיקציה האפידמיולוגית שהובילה לבדיקה | גיל, האם מקצוע הנבדק כולל חשיפה גבוהה לחולים, האם הנבדק היה במגע עם חולה מאומת. |
| מדדים גופניים | חום גוף, דופק, לחץ דם (סיסטולי ודיאסטולי), מס' נשימות לדקה, סטורציית חמצן; תוצאות בדיקות מהירות לשפעת ולסטרפטוקוקוס אם בוצעו. |
| תסמינים קליניים | מס' ימים להופעת תסמינים;האם ההאזנה לריאות תקינה (ctab, lungs clear to auscultation), האם הופיעו קשיי נשימה, חרחורים (rhonchi), שריקות (wheezes), שיעול (כולל מידת החומרה של השיעול), חום, קוצר נשימה (כולל מידת החומרה), שלשול, עייפות, כאבי ראש, אובדן ריח, אובדן טעם, נזלת, כאב שרירים, כאב גרון. |
| נתוני קומורבידיות | האם סובל מסוכרת, מחלת לב, יתר לחץ דם, סרטן, אסטמה, חסימה ריאתית כרונית, מחלה אוטואימונית. |
| נתונים על הבדיקה | סוג הבדיקה: Rapid COVID-19 Test, SARS COV 2 RNA RTPCR, SARS COV2 NAAT, SARS CoV w/CoV 2 RNA,SARS-CoV-2.מקום דגימת המטוש: Nasal, Nasopharyngeal, Oropharyngeal. |
| תוצאת הבדיקה | חיובי / שלילי לקורונה. |
התפלגות הגילאים של הנבדקים מראה, כצפוי, התפלגות נורמלית בקירוב, כאשר החלק השמאלי של ההתפלגות "קטום" ומראה מעט מאוד נבדקים בטווח הגילאים 0 – 20, כנראה בשל העובדה שילדים ובני נוער אינם חולים הרבה בצורה סימפטומטית בקורונה. ניתן לראות הבדל בין התפלגות הגילאים של הנבדקים החיוביים לשליליים, מה שעשוי להעיד על רלוונטיות של המאפיין הזה (גיל) לניבוי.

מדדים גופניים כגון חום גוף ודופק – מראים גם הם התפלגות נורמלית בקירוב והבדלים מסויימים בין הנבדקים החיוביים לשליליים. בהיות הדאטה לא מאוזן – קבוצת הנבדקים השליליים היא הקבוצה הדומיננטית והיא מכתיבה את צורת ההתפלגות של הדאטה-סט כולו:

ערכים חסרים – הדאטה-סט כולל לא מעט ערכים חסרים, ככל הנראה בשל צורת התיעוד ואיסוף הנתונים. בתרשים מס' 3 להלן נציג את התפלגות הערכים החסרים (מאפיינים להם אין ערכים חסרים לא מוצגים בתרשים).

ניתן להתרשם כי ישנה קבוצת מאפיינים של תסמינים ומאפיינים שאינם מדווחים עבור מרבית הבדיקות – ובפרט כאב גרון, כאב שרירים, נזלת, אובדן טעם וריח, כאב ראש, עייפות, שלשול, תוצאת בדיקה מהירה לשפעת ותוצאת בדיקה מהירה לסטרפטוקוקוס. סביר להניח שמרבית המודלים שיאומנו לא יעשו שימוש במאפיינים אלו. בנוסף, נשקול הרכבה שלהם בשלב הנדסת הפיצ'רים על מנת בכל זאת להפוך את ה"אות" האצור בהם למידע שימושי.
בנוסף, ניתן לראות כי עבור כל מאפיין – אחוז הערכים החסרים של קבוצת הנבדקים החיוביים מתוך הערכים החסרים של כלל הנבדקים הינו קבוע בקירוב – ומייצג בקירוב את היחס בין הנבדקים החיוביים לכלל הנבדקים (6.3%). ניתן לראות זאת בבירור בתרשים הימני – הרוחב של העמודות האדומות קרוב מאוד לקו הכתום המייצג ערך של 6.3%. החריג היחיד הבולט מכך הינו הנתון על דופק, שם ניכר דיווח חסר עבור נבדקים חיוביים – אולם מהתרשים השמאלי ניתן לראות כי אבסולוטית ישנו מספר קטן מאוד של בדיקות עבורן הדופק לא מדווח.
ניתוח זה של הערכים החסרים מחזק מאוד את ההערכה שהדאטה-סט הוא איכותי – שכן אינו מכיל הטיית אי דיווח לטובת הנבדקים החיוביים או הנבדקים השליליים (הטיית Missing not at random). בניגוד לדאטה-סט שפורסם על ידי משרד הבריאות הישראלי, כאן אין לנו סיבה לחשוש כי הנבדקים החיוביים סובלים מדיווח יתר או מדיווח חסר של מאפיינים כלשהם כגון תסמינים.
בתרשים מס' 4 להלן נציג את הקורלציה בין המאפיינים השונים.

ניתן להתרשם כי מרבית המאפיינים אינם בקורלציה האחד עם השני – וזו תכונה רצויה היות והיא מגדילה את פוטנציאל הניבוי של כל מאפיין בפני עצמו. בנוסף, ניתן לראות כי אף אחד מהמאפיינים אינו בקורלציה חזקה עם משתנה המטרה (תוצאת הבדיקה) – זאת אומרת שהמודל שלנו יצטרך "לעבוד קשה" וללמוד יחס לא טרוויאלי בין מאפייני הקלט לבין משתנה המטרה. אם, למשל, רוב מי שנדבק בקורונה סובל מחום גבוה, ורוב מי שסובל מחום גבוה ונבדק לקורונה אכן נדבק בקורונה – היינו אמורים לראות קורלציה חזקה בין המאפיין חום לבין תוצאת הבדיקה. היעדר קורלציה ישירה שכזו מעיד על כך שהקשר בין משתני הקלט למשתנה המטרה, אם קיים, אינו טרוויאלי. היעדר הקורלציה בין המאפיינים למשתנה המטרה גם מצמצמת את החשש שהתרחשה "דליפה" של אינפורמציה ממשתנה המטרה לתוך אחד המאפיינים האחרים.
ניתן לראות שלושה "גושים" של פיצ'רים בקורלציה חזקה יחסית:
- הגוש במרכז של המאפיינים הנשימתיים (המאפיינים ctab, rhonchi, wheezes, cough הם כולם מאפיינים נשימתיים – ולכן קורלציה חזקה ביניהם, חיובית או שלילית, היא צפויה).
- הגוש הכהה מימין למטה הינו של תסמינים כגון עייפות, כאב ראש, שלשול, אבדן טעם וריח, נזלת, כאב שרירים וכאב גרון – אלו תסמינים נדירים יחסית בדאטה-סט (ראינו בתרשים מס' 3 כי רוב הרשומות חסרות דיווח של תסמינים אלו) – מה שיכול להסביר את הקורלציה ביניהם.
- הגוש הבהיר בפינה הימנית התחתונה מייצג קורלציה אלמנטרית בשל הקידוד One hot שקידדנו את המשתנה הקטגוריאלי של סוג הבדיקה וכן קשר צפוי, כנראה, בין סוג הבדיקה למקום בגוף ממנו נלקחת דגימת המטוש.
עיבוד מקדים
הדאטה-סט פורסם בפורמט CSV, וכלל משתנים מסוגים שונים – מספריים, קטגוריאליים, בוליאניים וכו'. ביצענו "ניקוי" פשוט ובסיסי של הנתונים, שכלל:
- השמטת הרשומות עבורן תוצאות הבדיקה לא ידועות (הייתה רשומה אחת כזו).
- טרנספורמציה של כל הדאטה-סט למשתנים מספריים (משתנים קטגוריאליים קודדו ב- One Hot Encoding).
- השלמת ערכים חסרים – כאמור, חלק מהנתונים חסרים. ביצענו השלמה פשוטה ונאיבית של הערכים החסרים באמצעות ממוצע הערך של כל מאפיין.
הערה: ההשלמה בוצעה תוך שימוש בכלל הנתונים, מה שמייצר "דליפה" (Leakage) מסויימת מסט המבחן לסט האימון. בגלל שהדאטה-סט קטן בחרנו להתעלם מבעיה זו (שהאפקט שלה צפוי להיות זניח להערכתנו). ביצענו בדיקת רגישות וראינו שאכן, גם כאשר מבצעים השלמת ערכים חסרים ללא דליפה – ביצענו השלמה לערך קבוע שרירותי של 0.5 – ההבדל בביצועים הוא זניח (פחות מ- 0.01 הבדל ב- AUC, נבדק בולידציה צולבת).
בראייה קדימה – שיטות מתוחכמות יותר להשלמת מידע חסר (Data Imputation) עשויות לשפר במעט את התוצאות.
לאחר שסידרנו וניקינו את הדאטה, ניגשנו למשימת "הנדסת המאפיינים" (Feature Engineering). בחרנו להנדס, בנוסף למאפיינים המקוריים, מספר קטן של מאפיינים סיכומיים – סכומים ומכפלות של מאפיינים שמקובצים לוגית לאותה הקטגוריה. כך, למשל, הוספנו מאפיין שסופר את מספר התסמינים מהם סובל הנבדק, ומאפיין שמכפיל בין המדדים החיוניים (דופק, לחץ דם וכו') לכל נבדק. בראייה קדימה בהחלט ניתן לשקול הנדסת מאפיינים בכמות ובמורכבות גדולה יותר על מנת לשפר את המודל.
בחירה בסיסית של מודל חיזוי
בחרנו לאמן מודל חיזוי מסוג Random Forest – אנסמבל של עצי החלטה שמקבלים החלטת קלסיפיקציה בינארית – חיזוי תוצאה חיובית או שלילית לקורונה. בחירה זו נעוצה בכך שמודלי Random Forest טובים יחסית בהכללה וקלים יחסית לרגולריזציה והימנעות מ- Overfitting, הן בשל ארכיטקטורת האנסמבל הבסיסית שלהם והן בשל היות תהליך האימון מבוסס Bagging.
סיבה נוספת לבחירה במסווג Random Forest היא הקשר האינטואיטיבי בין המודל החישובי המבוסס על עצי החלטה לבין ההתוויות הרפואיות. ההתוויות הרפואיות בפרט, ובני אדם בכלל, עושים שימוש נרחב בעצי החלטה – סטים היררכיים של תנאי "אם… אז…". כך, למשל, ניתן לתאר את ההתוויות הנוכחיות לביצוע בדיקה לקורונה כעצי החלטה פשוטים. לדוגמה: היית במגע עם חולה מאומת? המגע ארך מעל 15 דקות והיה קרוב מ- 2 מטרים? אתה סובל מחום גבוה? לך להיבדק לקורונה. עצי החלטה אנושיים, כגון ההתוויות לבדיקה, גם אם נכתבים על ידי מיטב המומחים ומתבססים על הרבה דאטה – נוטים להיות עצים פשוטים מאוד – שכן הרבה יותר קל להפריך או לאמת את התוקף של עץ פשוט והרבה יותר קל להסביר אותו לציבור. מודלים חישוביים כגון Random Forest מצטיינים בלמידה של עצי החלטה מורכבים ועמוקים מכמות גדולה של דאטה, ולפיכך ניתן לראות בהם, במידה מסוימת, כהרחבה של ההתוויות הרפואיות האנושיות. אם נאמן מסווג Random Forest וניווכח שהוא עובד טוב – נוכל בהמשך לנסות לעשות לו "שיחזור הנדסי" ולנסות לחלץ ממנו לא רק את יכולת החיזוי שלו אלא גם הבנה רפואית מסוימת על הנגיף (Model Explainability).
בחרנו לקבע מראש היפר-פרמטרים בסיסיים של המודל (Hyper Parameters) ולרוץ איתם לכל אורך הניסוי. בחירה מדויקת יותר של היפר-פרמטרים עשויה לשפר את תוצאות החיזוי, אולם בשלב הזה בחרנו לא להשקיע בכך אנרגיה. זאת משתי סיבות מרכזיות:
- הדאטה-סט שברשותנו הוא קטן יחסית. אין לנו מספיק רשומות על מנת לבצע חיפוש נרחב במרחב ההיפר-פרמטרים מבלי לעשות שימוש במרבית הדאטה – ואז להסתכן שוב ב- Overfitting.
- המטרה שלנו היא לא "לסחוט" כל מיליגרם אפשרי של ביצועים מהדאטה-סט הזה. אנחנו לא מנסים לנצח בתחרות קאגל אלא רק לבחון את מידת הפרדקטביליות של האתגר.
ההיפר-פרמטרים המרכזיים שהגדרנו למודל:
- כמות גדולה יחסית של עצים באנסמבל (100) – למניעת Overfitting. הסבר: Random Forest מממש למעשה את תאורמת "חבר המושבעים" של קונדורסה – בהתקיים תנאים מסויימים, ההסתברות להגיע להחלטה נכונה על פי רוב פשוט גבוהה יותר מההסתברות להגיע להחלטה נכונה על ידי פרט בודד, וככל שחבר המושבעים (אנסמבל) כולל יותר מושבעים (מודלים, עצי החלטה במקרה שלנו) – ההסתברות לקבל החלטה נכונה גדלה.
- עומק מקסימלי רדוד יחסית של כל עץ (3 רמות) – לא לתת לעצים להעמיק יותר מדי ובכך "לשנן" את הדאטה.
- מישקול דגימות בשלב האימון (class_weight: balanced) על מנת להתמודד עם חוסר האיזון שבין כמות הבדיקות החיוביות לשליליות.
- מניעת חלוקות עדינות מדי, באמצעות הגדרת שני ספים שמונעים חלוקה (min_weight_fraction_leaf ו- min_impurity_decrease), שוב, על מנת לצמצם את ה- Overfitting.
אימון מודל – ולידציה צולבת
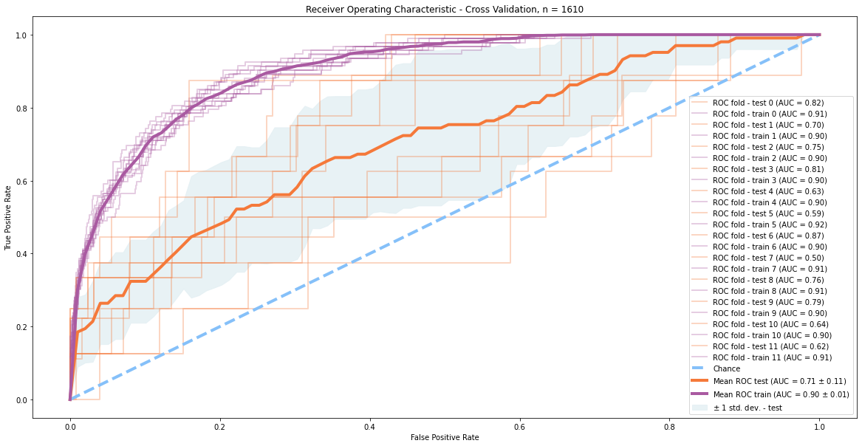
בשלב הראשון, ביצענו אימון של המודל תוך שימוש בגישת הולידציה הצולבת (Cross Validation). חילקנו את הדאטה-סט ל- 12 חתיכות, וביצענו 12 הרצות אימון. בכל הרצה אימנו מודל Random Forest על 11 חתיכות של הדאטה, ובחנו את ביצועי המודל על החתיכה החסרה (שלא שימשה לאימון). מיצענו את התוצאות ליצירת עקומת ROC ממוצעת – כפי ניתן לראות בתרשים להלן:

מה ניתן ללמוד מהתרשים?
- עקומת ה- ROC הממוצעת – הן על הרצות האימון (קו סגול) והן על הרצות המבחן (קו כתום) הינה טובה יותר מניחוש רנדומלי (קו תכלת מקווקו). זאת אומרת – למרות הדאטה-סט הקטן שברשותנו – אדם שניגש לבצע בדיקת קורונה אצל Carbon Health או Braid Health יעדיף להאמין לחיזוי המודל שלנו מאשר להאמין להטלת מטבע. בהתחשב בכך שאנשים אינם זכאים לבצע בדיקת PCR לקורונה ללא סיבה אלא נדרשים לעמוד בהתוויות מתאימות – זו תוצאה בכלל לא טריוויאלית!
- השטח מתחת לעקומה (AUC – Area Under the Curve) הוא 0.71 על הרצות המבחן ו- 0.90 על הרצות האימון. AUC הוא מדד נפוץ להערכת מודלי סיווג, היות והוא מתאר את כוחו של המודל ואינו רגיש לבחירה ספציפית של סף החלטה. הפירוש האינטואיטיבי של AUC=0.71 שהתקבל הוא שאם המודל שאימנו "יגריל" מסט המבחן (בו לא התבצע שימוש בשלב האימון) בדיקה חיובית אמיתית אחת ובדיקה שלילית אמיתית אחת – ויצמיד לכל אחת מהן ציון שמתאר את תחזית המודל לחיוביות (מספר בין 0 ל- 1 כאשר 0 מייצג תחזית שלילית מוחלטת ו- 1 מייצג תחזית חיובית מוחלטת) – יש סיכוי של 71% שהציון של הבדיקה החיובית יהיה גבוה מהציון של הבדיקה השלילית. כאמור, AUC מעל 0.7 נחשב מתקבל על הדעת, AUC מעל 0.9 נחשב מצויין. זאת אומרת שהמודל מראה בדיוק את מה שרצינו לבחון – פרדקטביליות של הפלט מתוך הקלט.
- בשקלול התמורות הידוע Bias-Variance Trade-Off המודל שלנו סובל מ- Variance גבוה יחסית ו- Bias נמוך יחסית. במילים אחרות, המודל שלנו סובל מהתאמת יתר (Overfitting) מסויימת להרצות האימון. סביר להניח שכיול מוצלח יותר של ההיפר-פרמטרים של המודל יוביל לאיזון טוב יותר בשקלול התמורות הזה, זאת אומרת יקטין את ה- AUC על הרצות האימון אבל יגדיל את ה- AUC על הרצות המבחן. כאמור, זו לא לגמרי המטרה שלנו בפוסט הזה ולכן נשאיר את הכיול העדין הזה לעבודה עתידית.
בתרשים שלהלן ניתן לראות את המאפיינים המרכזיים ביותר במודלים שנלמדו – Feature Importance. ניתן לראות כי המודל עושה שימוש במאפיינים מקטגוריות שונות (מדדים, תסמינים, מאפייני בדיקה) – עדות לכך שהמידע שנאסף אכן רלוונטי לבעיית החיזוי שלנו! בנוסף, ניתן לראות כי חלק מהמאפיינים המרכזיים תואמים את ההתוויות לבדיקת קורונה ואת האינטואיציה שלנו – למשל היות טמפרטורת הגוף מאפיין מרכזי. מעניין לראות שלסוג הבדיקה אין השפעה משמעותית – ככל הנראה עדות לכך שלמאפיין זה אין הטיה או השפעה בכיוון קבוע על תוצאת הבדיקה.

מהתרשים ניתן לראות, כאמור, כי לטמפרטורת הגוף משקל גבוה במודל שנלמד. ביצענו בדיקת רגישות גסה למאפיין הזה – השמטנו אותו מהדאטה-סט (ואת המאפיינים שהינדסנו שעשו בו שימוש) וביצענו סבב אימון נוסף של מודל בולידציה צולבת כאשר שאר הפרמטרים זהים. אכן ראינו הנחתה לא זניחה בביצועי המודל שנלמד (הנחתת AUC של 0.03 על חתיכות האימון ושל 0.04 על חתיכות המבחן). מסקנה: טמפרטורת הגוף אכן מהווה מאפיין ערכי בחיזוי תוצאת הבדיקה. בהמשך ניתן לבחון את השפעתם השיורית של כל אחד מהמאפיינים המרכזיים במודל (One At A Time Sensitivity Analysis).
תצפית מעניינת נוספת מתרשים ה- Feature Importances היא כי המאפיינים הסיכומיים שהינדסנו אכן באו לידי ביטוי במודלים שאומנו (vitals_sum_with_age, vitals_multiplication וכו'). מכיוון שהדאטה-סט שלנו קטן יחסית, מאוד הגיוני שמאפיינים שמקבצים את הסיגנל האצור במספר מאפיינים גולמיים אחרים יהיו שימושיים. זו בהחלט נקודה לשיפור עתידי – המאפיינים הסיכומיים שהינדסנו הם פשוטים ואינם עושים שימוש בידע רפואי מקדים (Domain Knowledge). סביר להניח שהינדוס מדויק יותר של מאפיינים טובים יותר ישפר את ביצועי המודל.
אימון מודל – חלוקת Train/Test
בשלב השני, ביצענו חלוקה "מסורתית" של הדאטה-סט לסט אימון וסט מבחן (80%-20%). זאת על מנת לקבל מודל אחד ולבחון את הביצועים שלו על דאטה שבו לא בוצע שימוש כלל בשלב האימון. גישה כזו מקלה במעט על נוחות ניתוח התוצאות – למרות שברור שהיא בסך הכל תת קבוצה של גישת הולידציה הצולבת שהוצגה קודם.
אימנו מודל עם בדיוק אותם היפר-פרמטרים מהשלב הקודם והתוצאה שהתקבלה (עקומת ה- ROC) מוצגת בתרשים הבא:

ניתן לראות שהתקבל מודל טוב על סט האימון (AUC=0.90) ומודל לא רע על סט המבחן (AUC=0.74). לא נתרגש יתר על המידה, סביר להניח שיש כאן מעט השפעה של מזל (כפי שראינו בהרצות הולידציה הצולבת, בחירה רנדומלית של חתיכות מבחן שונות מובילה לתוצאות שונות בצורה משמעותית, יכול להיות שבמקרה נפלנו על חתיכה קלה יחסית לחיזוי). עדיין, ניתן לראות שהתקבל מודל עם Variance גבוה יחסית ו- Bias נמוך יחסית.
כעת, נבחן את ההסתברויות שחוזה המודל. בתרשים שלהלן נציג פיזור של תחזיות המודל.

מהתרשים ניתן לראות שגם בסט האימון וגם בסט המבחן יש נטייה של נקודות אדומות להתרכז בצד ימין ונטייה של נקודות כחולות להתרכז בצד שמאל – זאת אומרת שהמודל לומר להפריד בין בדיקות חיוביות לשליליות. יתרה מכך, ניתן לראות שהמגמה הזו היא יותר מובהקת בסט האימון מאשר בסט המבחן (Variance גבוה). בנוסף, ניתן להתרשם כי ניתן להעביר ספי החלטה כאלו שיפרידו בין תוצאות מובהקות ללא מובהקות. למשל, אם ניקח רק תחזיות שערכן גבוה מ- 0.7 ונסווג אותן כחיוביות לקורונה, ואת כל שאר התחזיות נסווג כ"לא ידוע" – לא נסווג שום סיווג חיובי שגוי (False Positive) בסט האימון ובסט המבחן. לחילופין, אם נסווג את כל התחזיות שערכן נמוך מ- 0.3 כשליליות לקורונה, ואת כל שאר התחזיות נסווג כ"לא ידוע" – לא נסווג שום סיווג שלילי שגוי (False Negative). באמצעות "קטימה" כזו – כ- 10% מהבדיקות ניתנות לחיזוי ללא טעויות כלל! מנגד, ניתן לראות שקיימת כמות לא מבוטלת של תחזיות במרכז ההתפלגות – תחזיות שהמודל שלנו לא ידע לסווג כראוי.
תרשים הפיזור הזה מציג אינטואיציה טובה יותר לאיכות של המודל ולמשמעותן של עקומות ה- ROC שהוצגו קודם לכן. עבור כל סף החלטה שנקבע – בהנחה שאין לנו את הפריבילגיה לסווג "לא ידוע" ושאנחנו חייבים לסווג כל בדיקה לחיובי או שלילי – יתקבלו ארבע קבוצות של תחזיות – True Positive, True Negative, False Positive & False Negative. עקומת ה- ROC שהוצגה בתרשים מס' 7 קובעת בכל פעם סף החלטה אחר, ואז "סופרת" את ה- FP וה- TP – וכך נוצרת עקומת המענה.
נתבונן על אותם הנתונים, הפעם בצורה מרוכזת ונציג היסטוגרמה של תחזיות המודל (ממושקלת, על מנת לאזן את חוסר האיזון שבין הבדיקות החיוביות לבדיקות השליליות):

התרשים מציג בבירור שהמודל שלנו למד טוב את הדגימות המובהקות – בדיקות חיוביות במובהק או שליליות במובהק (הקצה השמאלי של ההתפלגות הכחולה והקצה הימני של ההתפלגות האדומה). אלו האיזורים בהיסטוגרמה בהם ניתן למצוא רק עמודות כחולות (בקצב השמאלי) או רק עמודות אדומות (בקצה הימני) – ללא חפיפה. עם זאת, התרשים מציג בבירור כי ישנו חלק גדול של דגימות, גדול יותר בסט המבחן מאשר בסט האימון, בהן יש חפיפה בין ההתפלגויות – זאת אומרת שהמודל שלנו לא ידע לסוג אותן נכון בצורה קונסיסטנטית – וכל שנותר לנו הוא לבחור אם אנחנו מעדיפים שגיאות מסוג False Positive (ואז נעביר סף נמוך יותר) או שגיאות מסוג False Negative (ואז נעביר סף גבוה יותר). אם המודל שלנו היה מודל סיווג מושלם ההתפלגות האדומה והכחולה היו זרות לחלוטין, ואז סף ההחלטה היה מפריד ביניהן בצורה מוחלטת – וכך מפריד בצורה מושלמת בין הבדיקות החיוביות לשליליות.
מסקנות
- ראינו כי קיים קשר מובהק בין הנתונים שתועדו בדאטה-סט של Carbon Health ו- Braid Health לבין תוצאות בדיקות ה- PCR לקורונה. ישנו קשר שאינו מתאר קשר מקרי בין הנתונים על התסמינים, המדדים, מאפייני הנבדק והבדיקה – לבין היות הנבדק חיובי או שלילי לקורונה.
- ראינו כי אימון מודל Random Forest פשוט יחסית על הדאטה-סט מאפשר לבנות מסווג שחוזה בצורה שיטתית את תוצאת הבדיקה בדיוק טוב יותר מאשר הטלת מטבע. אם ניקח בחשבון את העובדה כי אנשים זכאים לבצע בדיקת PCR רק כאשר יש חשש אמיתי שהם נדבקו בקורונה – זו תוצאה לא טריוויאלית בכלל.
- ראינו שהמודל שאומן חוזה בצורה טובה את התוצאות "שבקצוות ההתפלגות" – הבדיקות החיוביות במובהק והבדיקות השליליות במובהק. זאת אומרת שסביר להניח שעם מאמץ קטן מאוד ניתן כבר עכשיו להשתמש במודל (או במודל דומה) על מנת לתעדף מועמדים לבדיקות ועל מנת לקבל החלטות לגבי תת קבוצה מתוך קבוצת הנבדקים הפוטנציאליים (הקבוצה המובהקת). כך, למשל, נבדק שהינו "חיובי מובהק" לקורונה בבדיקה הוירטואלית שלנו – ניתן להנחותו על בידוד מחמיר גם לפני קבלת תוצאת בדיקת PCR חיובית. נבדק שהינו "שלילי מובהק" ניתן לחסוך את הצורך בבדיקת PCR עבורו.
- ראינו שהמודל שאומן אינו שלם ואינו חוזה בצורה טובה את התוצאות שבמרכז ההתפלגות. במרכז ההתפלגות ישנה התאבכות בין התפלגות החיוביים והשליליים, ולא מתקיימת הפרדה חזקה מספיק בין הנבדקים השליליים לחיוביים.
- גם ללא דאטה נוסף – סביר להניח שניתן לשפר את ביצועי המודל באמצעות כיול עדין ומדויק יותר של ההיפר-פרמטרים של המודל, באמצעות טכניקות מתקדמות להשלמת מידע חסר ובאמצעות הנדסת פיצ'רים נוספים מתוך הדאטה הקיים. להערכתנו פוטנציאל השיפור של מהלכים מסוג זה, אף שקיים, הינו נמוך יחסית (יוסיף נקודות בודדות ל- AUC).
- הגדלת הדאטה-סט – בכשני סדרי גודל (לכ- 100,000 בדיקות) לפחות – צפויה לשפר בצורה מאוד משמעותית את ביצועי המודל ולאפשר שימוש אמיתי בבדיקות וירטואליות מבוססות למידת מכונה. לא הוכחנו טענה זאת בניסוי זה, אולם הגדלת הדאטה-סט תאפשר לנו לאמן מודלים מורכבים וחזקים יותר תוך הימנעות מ- Overfitting ולפיכך צפויה לאפשר להגדיל בצורה משמעותית את יכולת הניבוי של המודל ואת ההפרדה בין ההתפלגויות של הבדיקות החיוביות לשליליות.
סיכום והמלצות
בפוסט הזה ובפוסט שקדם לו הראינו שקיים פוטנציאל ברור ומובהק בביצוע בדיקות וירטואליות, מבוססות למידת מכונה, לקורונה. הפיכת היכולת שהודגמה כאן מהדגמה ליכולת חיזוי אמיתית ומוכחת, להערכתנו, צפויה להיות מכפיל כוח של ממש במימוש תוכניות השחרור של המשק לשגרה בנוכחות קורונה ובשליטה בהתפרצויות נוספות של הנגיף, בעיקר מכיוון שתאפשר:
- תעדוף חכם של תור בדיקות ה- PCR המהוות צוואר בקבוק לניטור של קצב התפשטות המגיפה. שימוש במודל חיזוי יאפשר לבדוק קודם את מי שזקוק באמת לבדיקה.
- קבלת החלטות מושכלת ודיפרנציאלית לגבי חשודים בהידבקות טרם ביצוע בדיקת PCR. חשודים שלפי המודל הינם חיוביים במובהק – ניתן להתייחס אליהם כאל נדבקים בקורונה לכל דבר ועניין גם טרם קבלת תוצאת בדיקת ה- PCR ולהנחות אותם על בידוד מוחלט ועל מעקב רפואי הדוק. חשודים שהמודל חוזה שהינם שליליים במובהק – ניתן להתייחס אליהם כאל בריאים, או ליתר דיוק כאל לא חולים בקורונה, ולחסוך את הצורך בבדיקת PCR יקרה ומורכבת.
- הרחבת מערך הבדיקות והניטור ומתן יכולת לבדיקה וירטואלית לקורונה מבוססת דיווח עצמי של תסמינים ומדדים. כך, אנשים מן היישוב יוכלו לקבל החלטות לגבי ההתנהלות האישית והמשפחתית שלהם על בסיס ניהול סיכונים מושכל ולדעת, לכל הפחות בקצות ההתפלגות, מה הסיכוי האמיתי שהם חולים בקורונה.
- הגדלת הכמות האפקטיבית של הנבדקים – שילוב בין בדיקות וירטואליות לבדיקות PCR יגדיל משמעותית את כמות הנבדקים מבחינה אפקטיבית. בפוסטים קודמים בסדרה, כמות הבדיקות אותן נדרש לבצע בכל יום בישראל הוערכה ב- 30,000 עד 40,000 – זאת על מנת שכמות הבדיקות היומית תכסה את קצב ההדבקה כך שכמות הנדבקים המאומתים תהיה מדד אמין למצב התחלואה. ברור כי ביצוע עשרות אלפי בדיקות PCR ביום מהווה אתגר ענק – הן בהיבט הביצועי-לוגיסטי והן בהיבט הכספי. בדיקות וירטואליות יאפשרו הגדלת הכמות האפקטיבית של הנבדקים תוך צמצום הנטל הלוגיסטי והעלויות הכספיות.
- ניטור מהיר ואפקטיבי של מצב התחלואה וקיצור "מעגל המשוב". בדיקות וירטואליות מספקות מענה סקלבילי (אינן מוגבלות בכמות) ומהיר (תוצאות תוך פחות משנייה). אחד מהאתגרים המשמעותיים בשיחרור המשק מן ההסגר הינו ב"מעגל המשוב" הארוך, שאורכו הנוכחי הינו מעל לשבועיים, לבחינת ההשפעה של מהלכי השחרור על מצב התחלואה. חלק מזמן המשוב הזה נובע מהזמן הארוך שלוקח לתאם, לבצע ולפענח את בדיקות ה- PCR. גם אם רמת הדיוק של הבדיקות הוירטואליות תהיה נמוכה מזו של בדיקות ה- PCR – הסקלביליות והמהירות שלהן יאפשרו להשתמש בהן כמדד טוב למצב התחלואה, ויקצרו את מעגל המשוב הארוך כל כך – ובפרט אל מול התפרצויות נוספות של הנגיף, אם וכאשר יתרחשו, בשבועות הקרובים או בחורף הבא.
הפער היחיד העומד בינינו לבין מודל חיזוי איכותי מאוד ומוכח הינו פער של דאטה – ולא פער טכנולוגי!
מומלץ לאסוף, לטייב ולפרסם לציבור דאטה-סט מדוקדק של מאפייני בדיקות ונבדקים. ניתן לקבל השראה מהחברות האמריקאיות Carbon Health ו- Braid Health שפרסמו דאטה-סט לתפארת מדינת קליפורניה.
מדינת ישראל יכולה להוביל ולהוות כוח חלוץ בהנגשת מידע – מידע שיאפשר אימון מודלים לחיזוי תוצאות הבדיקה לקורונה ברמת אמינות גבוהה מאוד!
בכל יום מתבצעות במדינת ישראל כ- 10,000 בדיקות PCR – זאת אומרת שבכל יום ניתן לצבור ולפרסם דאטה גדול פי 10 מהדאטה-סט הקטנטן עלינו ביצענו את הניסוי הנוכחי! השאלון האנונימי שפותח במכון ויצמן יכול להוות בסיס מצויין למאמץ התיעוד – אם נגזרת שלו תוכוון ספציפית אל קהל הנבדקים ואם הוא יועשר במדדים הנלקחים סביב הבדיקה ובתוצאות הבדיקה.
גם אם כבר מתבצעים במשרד הבריאות מאמצים של תיעוד מדוקדק של מאפייני הבדיקות, וגם אם כבר מתבצעים בתוך המשרד תהליכים של אימון מודלים של למידת מכונה על הדאטה – טיוב הדאטה ופרסומו לציבור הרחב יאפשר להגדיל בצורה דרמטית את הקצב ואת האפקטיביות של השימוש בו. בארץ ובעולם יש עשרות אלפי דאטה-סיינטיסטים שאימון מודלי למידת מכונה הוא המקצוע שלהם ושאין דבר שהם ישמחו לעשות יותר מאשר לרתום את הידע הזה לשימוש הציבור, ובפרט לטובת האצת מהלכי היציאה מן ההסגר תוך שמירה על בריאות הציבור!
ניתן לשמור על אנונימיות הנבדקים – בדיוק כפי שביצעו החברות האמריקאיות – ועם זאת לפרסם דאטה איכותי, עשיר, מפורט, אינפורמטיבי וחסר הטיות. פרסום של דאטה פתוח יאפשר לשכנע גופים נוספים בעולם לפרסם מידע כזה, וצפוי לייצר מעגל משוב עם הגבר חיובי: דאטה -> מודלים -> דאטה עד לסחיטת הביצועים לקצה גבול יכולת הניבוי והתכנסות למודלי למידת מכונה שיסייעו בצורה משמעותית בניהול השגרה בנוכחות הקורונה, בניטור התפרצויות עתידיות נוספות של הנגיף, בשליטה בתחלואה ובצמצום העלות הכספית של הבדיקות.
קישורים
- קישור לאתר שבו מפורסם הדאטה-סט.
- קישור למחברת (Colab Notebook) עם הקוד ששימש להכנת ניתוח זה.
- קישור לפוסט הקודם בסדרה.
- קישור לדאטה הפתוח שמפרסם משרד הבריאות לגבי נגיף הקורונה.
הפוסט נכתב על ידי עומר קורן, מנכ"ל חברת ווביקס. ווביקס מתמחה בפיתוח מערכות ומודלים למיצוי מידע בהתבסס על קוד פתוח ודאטה פתוח.
ברצוננו להודות לעידן ברק, לרמי פוגץ' ולע. דהן על הערותיהם המועילות.
הפוסט נערך ומתפרסם כחלק מפעולתו של צוות מחקר ו- AI במפא"ת המובל על ידי ע. דהן.
